Language: Java
Date: 2001 (released 2003)
Licence: GPL
Platform: Any JRE
In my spare time I wrote a library in Java that can recognise areas of an input image that are likely to contain text. The algorithm used to find areas of text is one I designed myself.
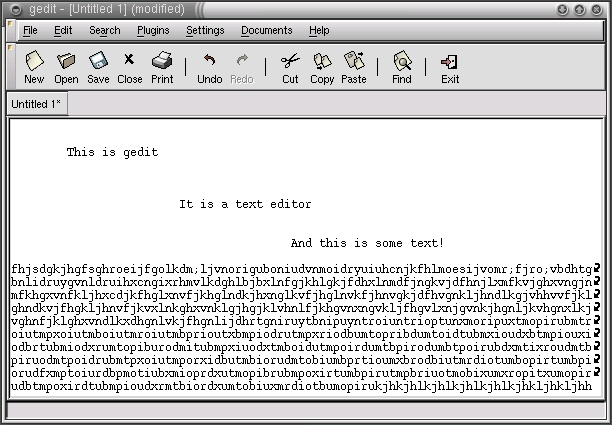
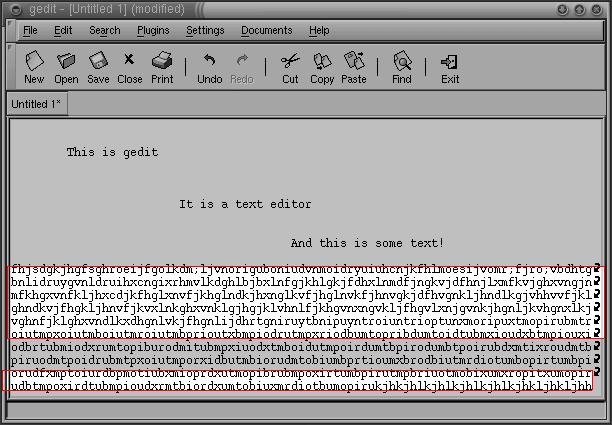
The table below contains the results of some test runs of the library. The parameters of the program were kept constant for the whole series of images in the assumption that, to be really useful, the program should not assume the luxury of a user being available to adjust parameters for each image. I have included some tests that didn't work very well to illustrate the limitations of the program. However, the parameters can be adjusted so that the textual regions in each image are correctly identified.
| Input | Output | Input | Output |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
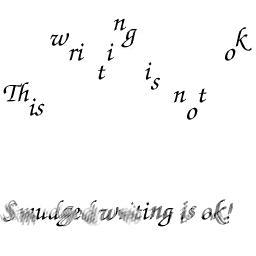 |
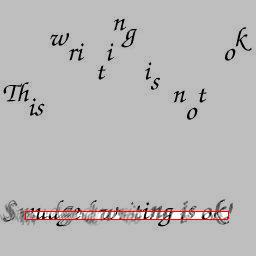 |
 |
 |
 |
 |
 |
 |
 |
 |
So how does the algorithm work? It starts by ignoring most of the information in the image, and concentrating on the contrast. For example, the two images below show a typical input image, and its contrast as seen by the library.
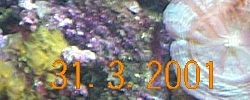 |
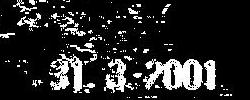 |
Next, imagine drawing two graphs: On one of them, we'll plot x against the sum of the contrast on column x. On the second graph, we'll plot y against the sum of all the contrast on row y. We can use these two graphs to draw some boxes around areas that will be likely to contain text. Every time the contrast rises sharply with a change in x, we mark that position as the left hand side of a box. When the contrast falls, we mark the position where it falls as the right hand side of a box. We do the same for y to get the tops and bottoms of the boxes.
We'll now have a pretty large set of boxes and we need to reduce this set down to give our final result. The algorithm has several rules for merging, shrinking, and deleting boxes using measures like aspect-ratio, mass (the amount of contrast enclosed by the box), density (mass/area), etc.
The library is licensed under the GPL, and you can download it here. You can compile the program by typing
javac GetImageText.java
To run the program, type
java GetImageText inputfile outputfile
where inputfile and outputfile are the (.jpg) input and output files.
Thanks very much to Daniel Morrione for encouraging me to release this software.